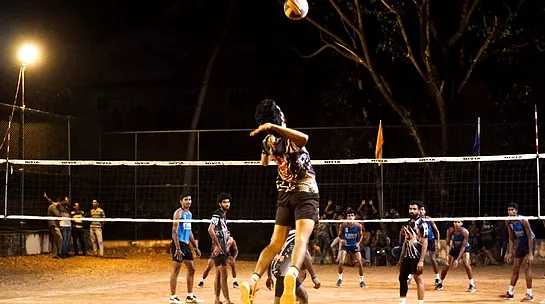When the mind begins to experience the sensation of physical comfort, joy or satisfied desires; the intelligence has to act as a judge with consciousness as mediator
T K M College of Engineering, the fondly remembered alma mater of thousands of capable engineers worldwide, has for more than 60 years, shown how a visionary and his ideas can transform an entire nation’s educational aspirations
Higher Education in our country has been undergoing tremendous changes for the last two decades. In addition to the domain knowledge, what will drive today’s children to success is an innate understanding of the inter-connectedness and inter-dependencies that form the underpinnings of the global village.
The 18th house under the prestigious Back-to-Home project of TKM College of Engineering ... Read More
Arts
Hestia’20, the techno-cultural symposium, was the perfect blend of technology and creativity of students of TKM College of Engineering.
Awards & Accolades
Dr.K.L.Priya, Faculty, Civil Engineering Department, TKM College of Engineering was the lead chair for two sessions at the International Conference on Coastal Estuarine Research Federation (CERF), USA on 11 November 2021.
Sports & Games
The department of Physical Education aims at mass participation of students and staff in Sports and Games.
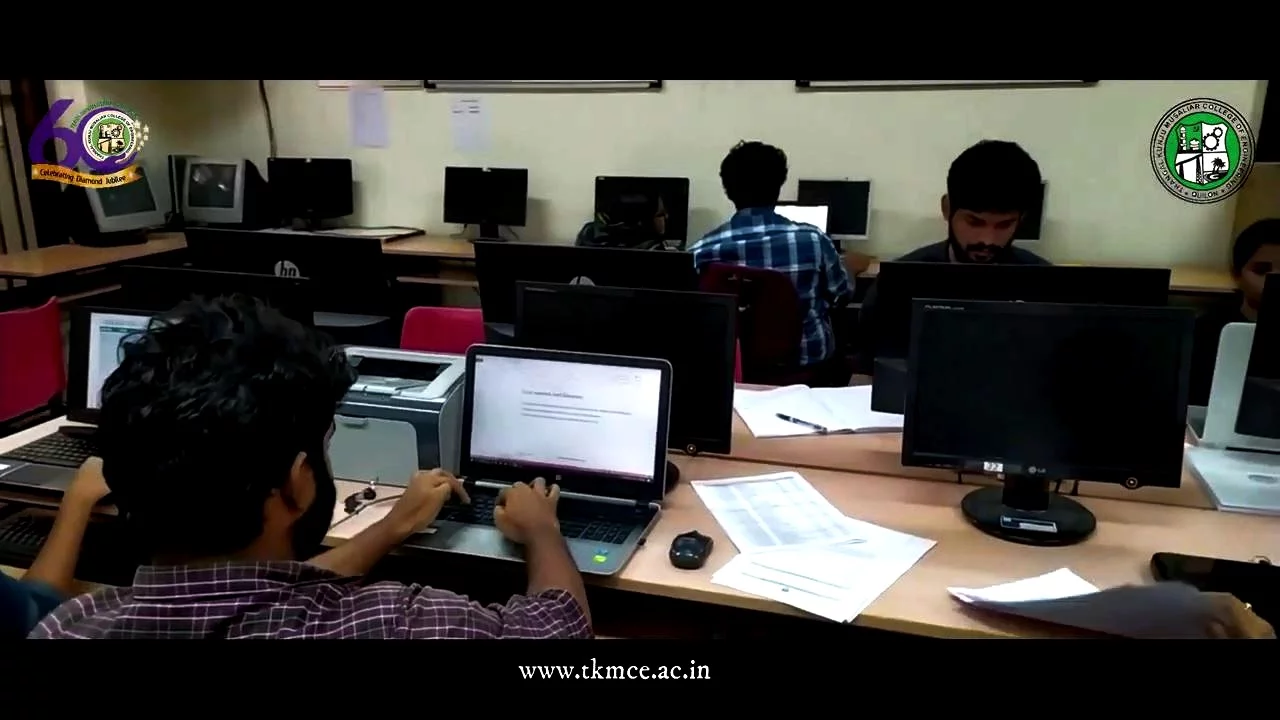
Academic excellence
Congratulations B. Arch Rank Holders KTU 2021 Batch
Arts
Hestia’20, the techno-cultural symposium, was the perfect blend of technology and creativity of students of TKM College of Engineering.
Dr.K.L.Priya, Faculty, Civil Engineering Department, TKM College of Engineering was the lead chair for two sessions at the International Conference on Coastal Estuarine Research Federation (CERF), USA on 11 November 2021.
Campus isn’t just a cloistered space where teachers chisel out future engineers. It’s a kaleidoscope of diversity, vibrance with its own unique heartbeat ...